 River's Edge Niezależne i niekomercyjne piśmiennictwo, muzyka, reportaże, wywiady, strefa retro i 8-bit.
River's Edge Niezależne i niekomercyjne piśmiennictwo, muzyka, reportaże, wywiady, strefa retro i 8-bit.
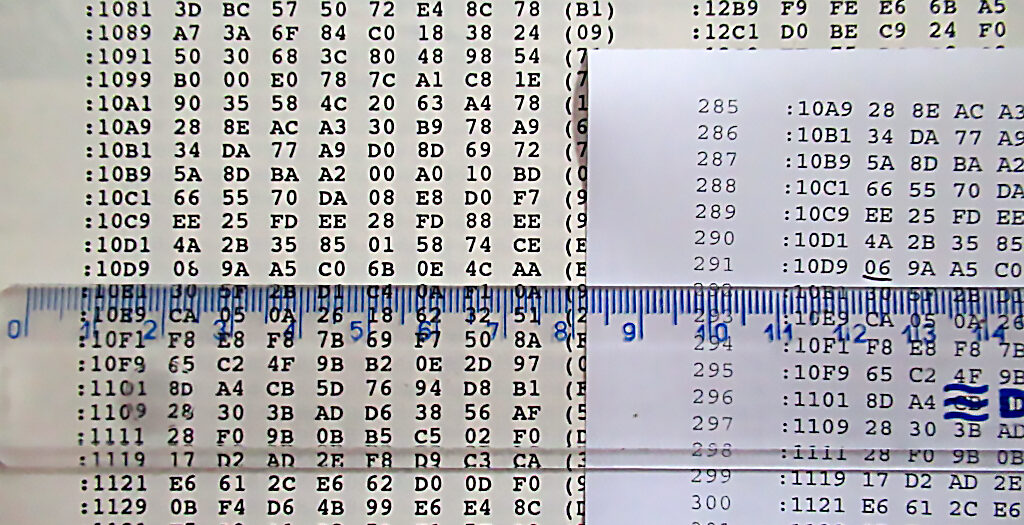
Historia czasem lubi zataczać koło. Czy opublikowany 30 lat temu listing kodu języka maszynowego może trafić ponownie do pamięci Commodore 64 bez ręcznego wklepywania cyferek i literek? Za chwilę przekonacie się, że jest to jak najbardziej możliwe.
Inspiracją do podjęcia działań na rzecz stworzenia konwertera „OCR to HEX” był listing programu „Kebab Disk Backup” opublikowany w numerze 2-3 czasopisma „Kebab” z 1992 roku. W przeciwieństwie do listingów znanych chociażby z „Commodore & Amiga”, dane zostały zaprezentowane w postaci heksadecymalnej bezpośrednio z monitora języka maszynowego. Zadaniem czytelnika wspomnianego przed chwilą numeru „Kebaba” było wklepać poszczególne wartości do pamięci Commodore 64, by uzyskać dostęp do programu autorstwa Silver Dreama ! Tego rodzaju wyzwania trenowały cierpliwość i skupienie. 30 lat temu zwyczajnie nie było innej opcji – należało po prostu siąść na wygodnym krześle i klepać linijka po linijce. Wystarczył do tego zwykły monitor zawarty np. w Black Boxie i około dwóch-trzech godzin intensywnej pracy przy komputerze.
Do wpisywania tego rodzaju listingów istniała specjalna wklepywaczka autorstwa Polonusa/Quartet o nazwie „Kebab-Korektor C64”, w której to program obliczał dla każdego wiersza sumę kontrolną. Pozwalała ona kontrolować poprawność wprowadzanych danych. W listingach publikowanych w „Kebabie” sumy kontrolne były umieszczane na końcu każdego wiersza. Bez nich wklepywanie danych np. w monitorze języka maszynowego mogło zakończyć się również jak najbardziej sukcesem i osobiście jestem ciekaw, czy komuś 30 lat temu udała się ta sztuka. Biorąc pod uwagę fakt, iż do dnia dzisiejszego „Kebab Disk Backup” był niemożliwy do ściągnięcia z Internetu, to podejrzewam, że nie.
Właściciel firmy Retronics zajmującej się wydawaniem reedycji czasopism, znany pod pseudonimem Duddie (nie mylić z Duddiem z Quartetu), pewnego dnia zapytał mnie, w jaki sposób przenieść wydrukowany w czasopiśmie kod języka maszynowego do pamięci Commodore 64. Gdyby był to listing w BASIC-u, to podobno sprawa byłaby zdecydowanie łatwiejsza, przynajmniej jeżeli chodzi o odpalenie programu w emulatorze. Tak jak wspominałem wcześniej – listingi prosto z monitora języka maszynowego nie były w odległych czasach czymś popularnym. W zdecydowanej większości w rodzimych czasopismach komputerowych publikowano listingi w BASIC-u, które zawierały procedury umieszczające we właściwej części pamięci dane pobierane z linii DATA. Czasami były to liczby dziesiętne, a czasami heksadecymalne. Nie ważne – rezultat zawsze był ten sam.
Dlaczego zatem w „Kebabie” listingi publikowano prosto z monitora? Odpowiedź jest teoretycznie prosta. Były to bowiem listingi programów skompresowanych, a przynajmniej takim był „Kebab Disk Backup z numeru 2-3/92. W takiej postaci listing po prostu zajmował miejsca, które w drukowanym czasopiśmie było ograniczone. Gdyby wspomniany program użytkowy miał być zaprezentowany w postaci niespakowanej, wówczas zapewne zajmowałby co najmniej kilka stron A4. Warto również w tym miejscu odnotować, iż „Kebab” nie był pierwszym czasopismem, który publikował listingi z sumami kontrolnymi. Podobno inspiracją do prezentowania programów w tym formacie było jedno z zachodnich czasopism pokroju „64’er”.
Jak zatem przy wykorzystaniu współczesnej technologii połączonej z nutką nostalgii przenieść listing kodu maszynowego z drukowanego czasopisma do pamięci Commodorka? Odpowiedź jest dosyć prosta. Należy sięgnąć po program użytkowy mojego autorstwa. Zanim jednak go odpalimy, należy wykonać kilka czynności przygotowawczych. W pierwszej kolejności skanujemy listing i wrzucamy skany do programu dokonującego optycznego rozpoznawania znaków (OCR). Naszym oczom powinien ukazać się listing w postaci tekstowej. Z bardzo dużym prawdopodobieństwem będzie on zawierał błędy. Najpopularniejsze błędy OCR to zamiana cyfry „1” na literę „l” (L jak Leokadia) oraz „5” na „s” (S jak Seweryn). Obie pary znaków są do siebie wizualnie bardzo podobne. W listingu programu „Kebab Disk Backup” po OCR znalazłem aż 33 literki „l” i 4 litery „s”. Po przywróceniu prawidłowych wartości dokonałem usunięcia wszystkich znaków z listingu, tak by zostały w nim jedynie cyfry i liczby odpowiadające ciągowi kodu języka maszynowego (0B0890069E323 itd.). Skasowałem także sumy kontrolne, ponieważ chciałem skupić się jak najszybszym transferze danych do pamięci Commodorka, bez dokonywania dodatkowych obliczeń.
Jak zatem usunąć niepotrzebne znaki z listingu? Najlepiej użyć do tego celu programu „Notepad++”, w którym poprzez przytrzymywanie lewego klawisza Alt można myszką zaznaczyć całą kolumnę i ją usunąć. Następnie usuwamy wszystkie spacje, a przejście do następnej linii kasujemy poprzez wyszukanie wyrażenia regularnego „\r\n”.
Po zapisaniu ciągu cyfr i literek zamieniamy rozszerzenie pliku na .prg i przenosimy go na obraz dyskietki .d64 np. za pośrednictwem programu „Dir Master” wydanego przez grupę Style. Następnie odpalamy program OCR to HEX” i dokonujemy w nim konwersji.
Pierwsze rezultaty konwersji mogą okazać się (i w moim przypadku okazały się) niepomyślne… Myślicie sobie pewnie, że w konwerterze są błędy? Nic podobnego. Błędy były, owszem, ale w pierwszym konwertowanym przeze mnie listingu! Okazało się bowiem, iż OCR dokonał jeszcze kilku zaskakujących modyfikacji i nasz listing z „Kebaba” zawierał trzy dodatkowe bugi. W ruch wnet poszła drukarka. Wydrukowałem listing po OCR i moich pierwszych poprawkach, wziąłem do ręki linijkę i linia po linii weryfikowałem wzrokowo poprawność listingu z oryginałem. I znalazłem… Bug w oryginalnym wydruku spowodował nieczytelność wartości #$08 z komórki $10d9, którą OCR rozpoznał jako #$06. Dodatkowo znalazłem dwa inne błędy. Wartość #$FB z komórki $1280 została zamieniona na #$FR (!), a z kolei #$FB umieszczone w komórce $0d47 zostało przez OCR zamienione na #$FE.

Ciężka praca wzrokowa okazała się bardzo potrzebna. Wyeliminowanie błędów powstałych podczas OCR pozwoliło przygotować finalną wersję listingu pod konwersję na HEX. Operacja udała się pomyślnie. „Kebab Disk Backup” uruchomił się bez błędów. Ale jak tu przetestować program, który w swoim założeniu służy do kopiowania dyskietek poprzez (prawie) zapomniane w dzisiejszych czasach połączenie równoległe (tzw. burst lub pararell)? Na szczęście w moich zasobach odnalazłem własnoręcznie polutowany kabel, który jeszcze kilkanaście lat temu używałem w trybie „dual burst”, czyli na dwie stacje. Po jego podłączeniu do pierwszej stacji okazało się, że kopiowanie nie działa. Dopiero na drugim egzemplarzu 1541 II „zatrybiło”. Zapewne w pierwszej stacji powstał zimny lut i aktualnie rozkręcanie całości w celu zdiagnozowania usterki nie było mi na rękę. Na szczęście kabel zadziałał z drugą stacją i program „Kebab Disk Backup” pozwolił mi skopiować po kablu szeregowym dyskietkę. Jak za starych czasów swappera, gdy przewalało się swoim kontaktom wiele produkcji dyskowych…
Tak więc dzięki mojej skromnej determinacji i pomysłowości stworzyłem program użytkowy, który umożliwia wykorzystanie rezultatów działania nowoczesnej technologii zamiany obrazu na tekst (OCR) do odtworzenia programu uwiecznionego za pośrednictwem listingu z monitora języka maszynowego w czasopiśmie sprzed 30 lat. Nadal jednak nic nie zastąpi potrzeby ręcznej weryfikacji rozpoznanych danych, w których z pewnością będą czaiły się błędy. Dlatego dla streszczenia przytoczę teraz etapy, jakie trzeba wykonać, by przenieść do pamięci Commodore 64 program zaprezentowany w postaci wydruku z monitora języka maszynowego w czasopiśmie:
1. Skanujemy listing i wrzucamy efekt skanowania do programu OCR.
2. Eksportujemy rozpoznane przez OCR dane do pliku .txt.
3. Odpalamy listing w programie do edycji plików tekstowych, najlepiej Notepad++ i przeglądamy wizualnie listing. Szukamy najpopularniejszych błędów, o których jest wspomniane w niniejszym artykule i je poprawiamy.
4. Drukujemy listing po pierwszych poprawkach bezpośrednio z Notepada++ (nie polecam przeklejać danych np. do Worda, bo się formatowanie rozjedzie) i porównujemy linia po linii dane z oryginalnym listingiem. Operację można również wykonać na ekranie monitora komputera.
5. Odnajdujemy ewentualne błędy, zaznaczamy na kartce, a następnie dokonujemy korekty w pliku .txt.
6. Usuwamy z listingu wszystkie dane, które nie są kodem języka maszynowego (wraz z wartościami sum kontrolnych). Rezultatem naszych działań jest ciąg liter i znaków. Na początku pliku dopisujemy dwa znaki, które będą traktowane jako adres startowy podczas ładowania. Jeżeli tego nie zrobimy, to C64 zje dwa pierwsze bajty z listingu.
7. Zapisujemy plik i przenosimy go na .d64, zmieniając mu wcześniej rozszerzenie na .prg.
8. Odpalamy konwerter i dokonujemy konwersji (jeżeli w listingu jest bug, to program przerwie konwersję i wyświetli stosowny komunikat).
9. Zapisujemy plik na dyskietce (program posiada podstawową obsługę błędów).
Gotowe!
TODO: Aktualna (i jak na razie jedyna) wersja programu OCR to HEX nie uwzględnia sumy kontrolnej drukowanej w czasopiśmie Kebab (trzeba ją również usunąć przy przygotowywaniu danych do konwersji). Powodem tego jest aktualny brak wiedzy w zakresie tego, jak ta suma była liczona. Być może w przyszłości powstanie druga wersja konwertera, w którym będzie ona weryfikowana.
Małą podróż w czasie zaaplikował Wam:
Paweł Ruczko (V-12/Tropyx)
Szczecin, 10.07.2022 r.